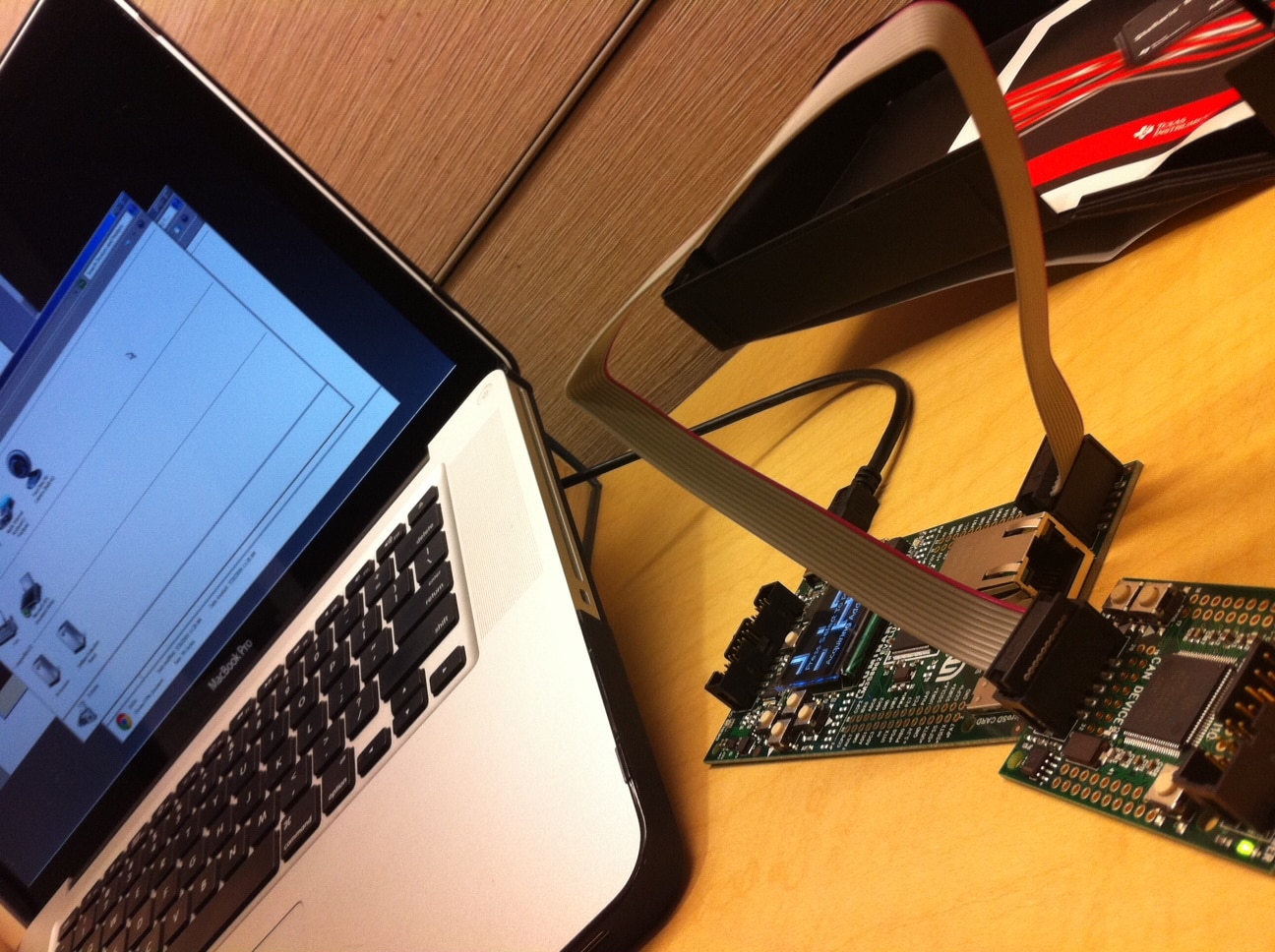
Quick update with the Embedded side project i’m doing.
It’s interesting to build a OS kernel from scratch. Nothing too fancy, but it’s quite an epiphany to realize that under all the complexity of Operating Systems is an array of void type functions that take a void pointer!
The coding part is very constrained due to hardware limitations. For instance, the first change is dynamic memory allocation. That is a no no. Everything has to be allocated statically.
Program Structure:
The main structure of embedded programs boil down to this:
// globals and static allocations
void main(){
// Initializations of Board
// Program specific initializations
while( TRUE ) {
// Runtime code
}
}
As you may have noticed, after initialization, the while loop runs forever. If you think about it, it makes sense as all embedded systems startup and stay on.
State Based OS:
The next inquiry that comes to mind is how do you maintain program flow or control? That is through “States”. The program architecture relies heavily on states. This makes the design of software on chips much more practical and controllable!
The first thing that I endeavored to add into my development environment was a robust state logging system. Whenever the chip crashed on me I just opened the debug log which hopefully got closed before the chip died. After that, it’s a simple traceback towards which state the chip crashed under.
The other cool aspect about states are self-stabilizing or self-correcting machines. By keeping track of which state we are in and how we got there, it is possible to backtrack from a “bad” and take the route that leads to a good state. Dijkstra’s Self Stabilization is a good starting point for implementing the latter, which leads us to the next topic of discussion….
Fault Tolerance:
The first thing I learned in Embedded in terms of tolerating faults, is that the chip cannot crash. Instead it needs to “fail gracefully”. What this means is that it needs to reduce functionality whenever the fault happens. This entails a layered system of execution where parts of the chip (Timers, Controllers, Sensors etc.) would be turned off after a fault has been discovered or encountered.
The main two ways of detecting faults are either through algorithmic or computed redundancy checks. Algorithmic redundancy use math and bit switching to uncover corrupted data. For example, a popular method is Cyclic Redundancy Check (CRC). Without getting too mathematical, what the technique uses are prime numbers. Due to their nature of being factored by only 1 or themselves, they are used to premultiply the bits and if at the receiving point when the data is checked, another number than the 1 or the prime number is a factor of the data, then the latter is corrupted. The nifty part about CRC checks is that due to our knowledge of the factors pertaining to prime numbers, we also know which bit to flip in order to fix the data!
This is by far one of the best methods out their to fix corrupted data, also widely used in hard drives.
Task Control Blocks:
The kernel of the realtime operating system (RTOS) is essentially made of an array of void function pointers that take a void pointer. The excessive use of voids, is too allow maximum generality. The void function pointers serve as callbacks to the functions added to the array or queue, and their void pointer arguments allows each function to take any structure as argument.
To organize this, a Task Control Block (TCB) is used.
typedef struct
{
void* taskDataPtr;
void (*taskPtr)(void*);
int delay;
}
TCB;
TCBs are basically ID cards for processes. Whenever a process is added, it comes in the form of a void function taking a void pointer. taskPtr takes the latter and its respective data’s address assigned to the taskDataPtr.
For example:
// Process's data
typedef struct {
int x,y,z;
} DataProcess0;
// Process function
void Process0( void *data ) {
// code
}
// Bind Function and its data to queue
queueTCB[0].taskPtr = Process0;
queueTCB[0].taskDataPTr = dataProcess0;
The above is a basic example to how tasks are added to the task queue. Now, the while loop shown at the top is where the queue/dequeueing happens. Here’s the evolved one.
while(1) {
ptr_TCB = &taskQueue[q_iter];
ptr_TCB->taskPtr( ptr_TCB->taskDataPtr );
q_iter = ( q_iter + 1 ) % TASK_CNT;
ScheduleMain( &scheduleData );
}
the q_iter variable increments at every loop and executes the next process in the queue. When the function pointer is called, it is fed its respective function or process data.
This basically is the kernel task queue which takes care of enqueueing and dispatching process very RTOSs. The process have to execute under a deterministic time due to the nature of the environment (compared to  non realtime operating systems such Windows, MacOS or Linux).
Memory Allocation:
Dynamic allocation in the embedded world is a big NO NO! Due to the deterministic nature of these applications it is common practice to allocate statically. Mallocs and Free are not to be used. They do work but due to the unpredictability of the dynamic allocation, it goes agains the very nature of the embedded decree.
All variables that will be used have to be declared and initialized at startup. This makes sense in perspective due to the nature of embedded systems. They startup and keep running forever. All the variables they’ll ever need  are determinable.
More tech talk in next Embedded related post!!